![]() BREAKING NEWS
BREAKING NEWS ![]() GPU hardware has gotten faster since 2015!
GPU hardware has gotten faster since 2015!

We might eventually need to push this up to 12 characters minimum. Also, for the love of {diety}, please never, ever create a numbers-only password. ![]()
All this fancy “make up a long pass phrase” talk is fine, until you have to start entering passwords on a mobile phone, and realize that mobile phones are probably the dominant form of computing for everyone, statistically speaking, moving forward.. the Chia project has a neat way of dealing with this, autocomplete for a set of 24 words:
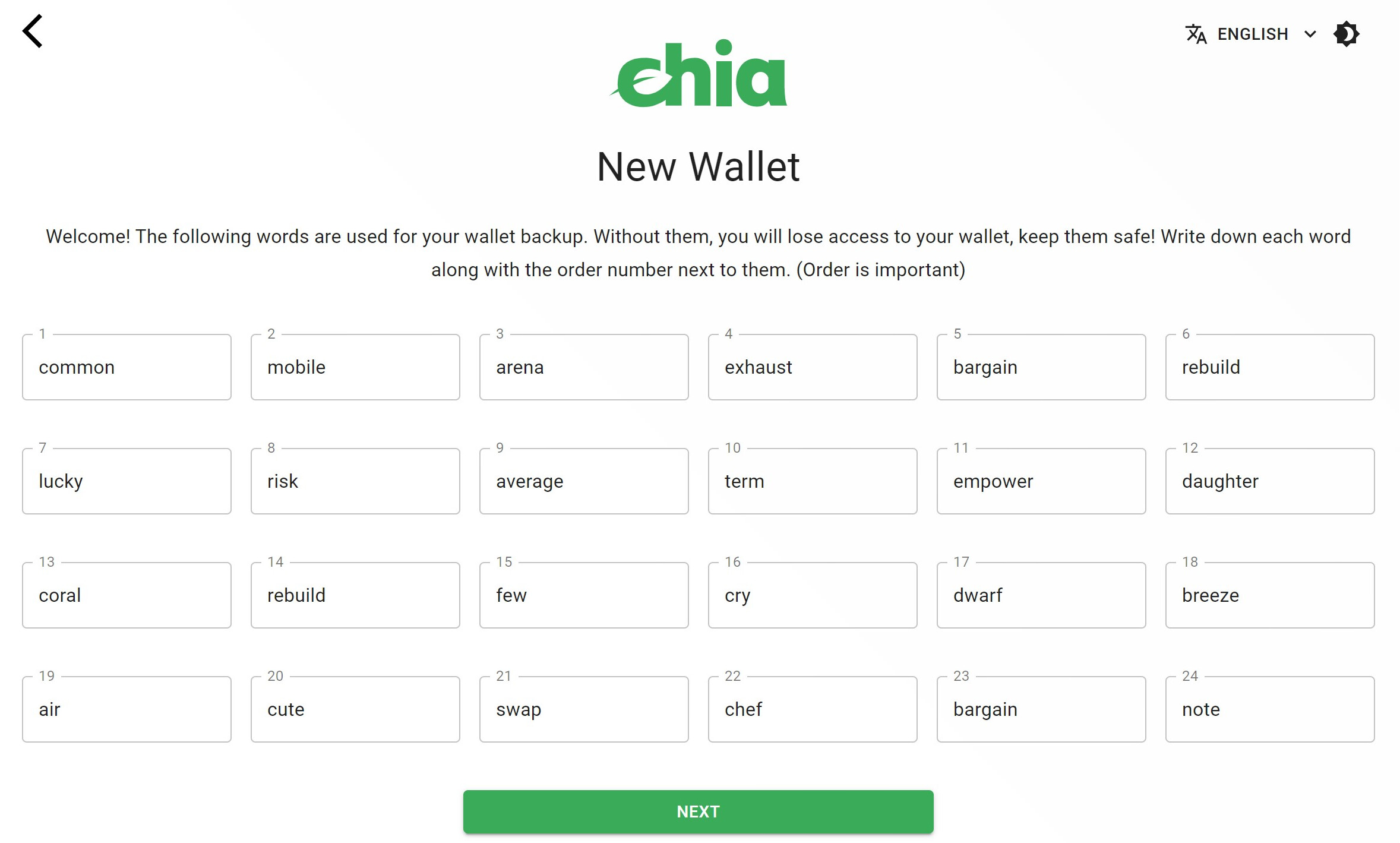
and here’s a random new one I generated
As you type, it autocompletes from the available words, so you only have to type a few characters from each word..
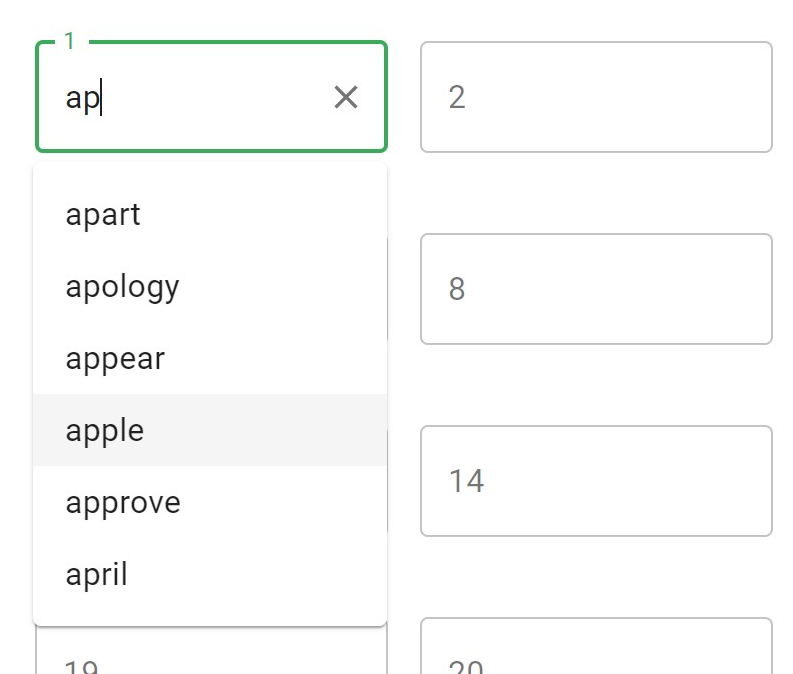
that’s really clever!