When we started Discourse in 2013, our server requirements were high:
This is a companion discussion topic for the original entry at https://blog.codinghorror.com/the-cloud-is-just-someone-elses-computer/
When we started Discourse in 2013, our server requirements were high:
I am unclear on why you think PC colocation isn’t widespread. I’ve worked for colo companies before, at various points in the last 20 years, whose userbases were 90-100% PC, mostly linux servers, often for game hosting purposes but sometimes for GPGPU operations.
That caveat is networking drivers. Our Discourse scooters were in critical incoming networking roles, in groups of 3 for redundancy. So they were getting clobbered with traffic 24/7, and every 6 months we’d get a weird kernel panic on one of them that we couldn’t explain.
I did not experience this for my colocated boxes which were literally identical parts – but also were driving a fraction of the network traffic in a totally 100% vanilla Ubuntu Server install – so I am thinking that the network stack for these off-brand networking chips can have some rough edges.
I’ve seen weird or off-brand network hardware cause really difficult to diagnose problems many times.. for example
Until a year ago I never really thought much about NIC vendors. I figured if you bought Intel or Broadcom you were safe, maybe if I was doing near Gigabit speeds constantly or iSCSI I would have to pay more attention, but other than that I figured I was good.
Man, was I ever wrong.
and here
Given the problems we’ve faced with third-party NIC teaming (link to above blog entry), I was gung-ho to get switched over to the native teaming features which I’ve monitored in production environments for over a year at that point. Having the network load-balancing and failover (LBFO) teaming included in the OS is a major plus.
I remember poor Geoff Dalgas spending WEEKS on this..
If you plan to put these boxes in critical / complex / heavy traffic network roles, make sure the network hardware is from a vendor you trust.
To continue my twitter comment: Supermicro microblades/microclouds are relatively common. Unfortunately this is the kind of thing where you have to “jump on a quick call” with a vendor to get an idea of ordering and pricing. Thinkmate actually has a fairly decent breakdown of the current Microblades here:
They do offer pricing on the Micrcloud systems here:
12x servers in 3U of space with 1TB of NVMe SSD disk, 64GB of ram and wicked fast network across a shared backplane with built in redundancy for about $1800/node is a pretty good value prop. If you’re willing to go to off-lease equipment the value gets even crazier. If you search ebay for “supermicro microcloud” there are almost always great deals to be had. Most colo places will offer you 3U of rack for around $150/month give or take.
I think the biggest downside is that SuperMicro wants you to populate the system completely when you buy it. It’d be more interesting if you could “buy as you go” so to say with a better vendor pipeline.
Relative to cloud hosting? Colocation is suffering mightily. That’s another reason you can get killer deals on colocation at the moment, because the competition with the cloud(s) is fierce and frankly the colocation facilities aren’t winning that battle.
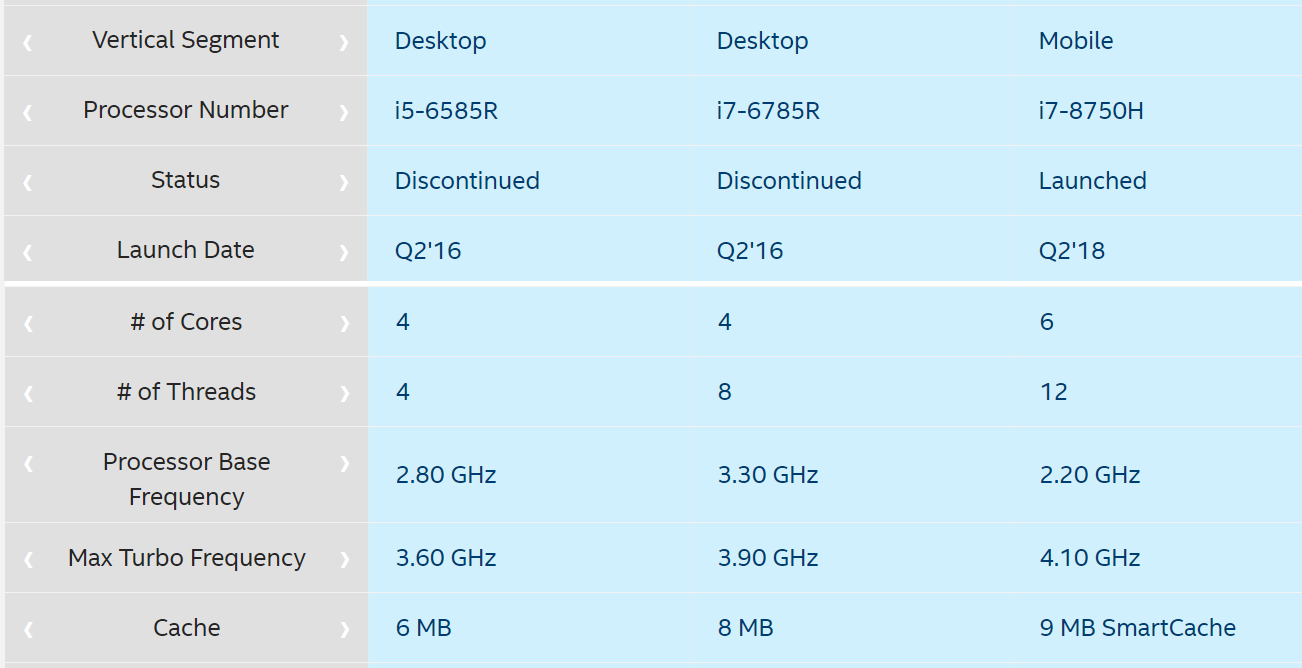
As an aside on the Partaker B19 Mini-PC, I just noticed that you can select one of three CPUs on the barebones box, and there’s a substantial price increase for each CPU tier:
![]() $290 vs $388 vs $490
$290 vs $388 vs $490
I find for colocation you do want to splurge a bit in that initial investment so the box ages more gracefully, but that bump from $290 (4 core, 4 thread) to $490 (6 core, 12 thread) is a big one – almost 50% of the total price.
Interesting how the higher end CPU is marked a “Mobile” part as well, and launched much later than the other two in 2018.
Also SPOILER ALERT these comments are rendered on the very Mini-PC being discussed in the blog post ![]()
Now this is a cool idea. I’m so young I have no experience with hosting that isn’t AWS and friends. I always assumed taking a machine and putting it into a data center was a relic of a bygone era. But this gives me ideas. I use Kubernetes extensively at work where we have a steady, CPU-intensive workload. And every month we pay a fortune to our cloud provider to use their nodes. It’s been years now that we’ve done this. If Kubernetes ever supports creating hybrid clusters that seamlessly allow you to auto-scale pods across co-located servers and cloud VPSs etc, we’ll have an amazing best of both worlds where we can cut our costs and get the on demand scale-ability we need.
There are real holes in the market here. Quality mini pc’s with intel nics? Simple cheap rackmount systems? I love 1/2 or 1/3 rack xeon-d systems (IPMI & 10GBase-T!) for our data center but no-one sells them.
Between a cloud instance (for which you don’t have to manage hardware at all, plus the ability to rent them for a very short time) and a colocated server, you can also rent a dedicated server. I don’t know for the US, but for example, at Hetzner, you can get an i7-6700, 64GB, 2x512GB of NVMe SSD for 34€ per month, making its cost for 3 years far below the colocated solution.
Yes, this is true, and Amazon started dipping their toes into dedicated hardware as well.. so the lines are further blurring.
Given the specs, I bet the per-minute pricing on those bare metal instances is indeed ![]()
Oh, well, now that you threw that out there, I just have to go into story mode. Gather 'round, kiddies, some graybeard’s babbling about how things worked back in the Jurassic. (And as an added bonus, I’ll probably end up revealing some things that were considered company secrets… 20 years ago… by a company I no longer work for… that doesn’t exist in the same form anymore… in an industry I also no longer work in. #NotWorried)
I have no small amount of experience with hardware colocation, for one simple reason: For two years back in 1997-1998, I was a member of the team that developed AOL’s dialup modem network (codename: “BigDial”).
Back in the days when AOL was accessed via dialup, and you’d call some local, toll-free number to connect without paying long-distance charges, how do you think your call connected to the AOL servers? Even for those old enough to have used the internet that way, you probably never really thought about the connection path. You just called,and it worked. But, how?
I’ll give you a hint: It didn’t involve the telco somehow magically transporting your call to some central server somewhere.
Nope, for AOL to have toll-free access numbers in every local calling region in the country meant having modems physically placed within every local calling region in the country, in a location where the local telco could deliver a bundle of phone lines (digital lines — a requirement for 56K dialup was that the server end had to be digital) that had been assigned a local phone number, and for which they did absolutely nothing special with the routing. The local calls were local because they were local, and no matter where you were located the modems you called were probably somewhere within an hour or two’s driving distance, max.
Hence, BigDial. 350,000 modem ports scattered all around the country, in literally hundreds of wildly heterogeneous facilities. We preferred dedicated co-location facilities where available (MCI operated quite a high percentage), but unsurprisingly not every local calling area in the country is home to a well-run, fully-provisioned, 24/7-staffed professional colo operation. So, where we couldn’t get into a colo, we started casting about for alternative options… when desperate enough, literally anyplace that would sell us floor space that we could get hooked up with both power and data. Hotel basements, wiring closets, you name it… I visited one site where we were sharing the server room for a local weekly newspaper office.
Into all of these environments, we introduced one or more standard units of modem service: The BigDial rack. See, we didn’t just co-locate computers, we co-located entire 7-foot cabinets packed full of dialup hardware in ever-increasing port densities — fewer than 400/rack, in the earliest hardware iteration, up to (IIRC) 1152/rack by late 1998. The cabinets used 3Com/USRobotics Total Control enterprise hardware, and we contracted 3Com to build them for us to our detailed specs. (How detailed? We had custom cable sets built for each rack, 7 distinct jacket colors and every cable cut to an exact length in inches, and we spec’d the placement of every individual cable and screw in the rack. Even the cable routing was dictated, though we gave them free reign on placement of the zip ties.)
All of this is a roundabout way of saying that, with all due respect to Jeff, I’m somewhat skeptical of the argument in favor of owned-server colocation. “Mac users do it!” also doesn’t strike me as a very convincing argument.
We built BigDial the way we did because we had to, there was literally no other option. Which is exactly the same reason Mac people co-locate computers rather than taking advantage of nonexistent virtualization and shared-hardware offerings. It’s not because they’ve crunched the numbers and decided on that course of action, it’s because there is literally no alternative if you’re looking for hosted MacOS-platform services.
Obscene amounts of work went into ensuring remote management for the BigDial systems on both the software and hardware level, and into making the hardware as reliable as possible without ever needing human intervention, since many of the racks were housed in locations where on-site support could not be relied upon.
(One last story tangent: The first iteration of the platform used an AIX server, since Total Control didn’t yet offer a server blade, and because that machine had no redundant power option the first-gen racks were outfitted with a big, beefy server UPS at the bottom. That seemed like a great idea, until 5 years later when all of those UPS batteries reached the end of their life, and had to be replaced. Which meant visiting every single one of those first-gen racks to perform a battery swap, and that’s how I found myself in that newspaper office server room one Sunday morning at 2:00am for a maintenance window.
Also, fun fact: those rack-mountable server UPSes are basically big drawers full of batteries, and if you have a drawer full of heavy parts mounted in a rack that’s been shipped cross-country before installation, there’s no way to know what shape that drawer is really in. I still have flashbacks to pulling the handle on the UPS and hearing the clatter of dozens upon dozens of ball bearings as they rained down onto the raised flooring below the cabinet.)
These days, even needing virtual server capacity in a hosting environment is growing increasingly rare. Many “cloud” consumers are perfectly happy with SaaS, PaaS, or IaaS offerings, paying for only the capacity they actually consume (whether it’s measured in transactions, kilobytes, or what have you). As with cloud storage offerings, there’s a lot to be said for not having to manage the hardware in any way.
There are cloud storage systems (OwnCloud) where you can build a storage cloud using your own server hardware, but I can’t conceive why anyone would really want to do that when it involves maintaining all of the physical storage yourself. I don’t want to have to think about monitoring hard drive lifecycles, replacing failed drives, and ensuring data integrity — I’m happy to let companies like Google and BackBlaze deal with that nonsense. Yes, cloud storage is “just somebody else’s hard drives”… and that’s the best thing about it!
I just booted up a $160/month (32GB, 8 vCPU, 640GB SSD) Digital Ocean instance for testing, and compared to the 2019 mini-PC which is “only” 6 core / 12 thread.
sysbench cpu --cpu-max-prime=20000 run
4,086 vs 5,671
sysbench cpu --cpu-max-prime=40000 --num-threads=8 run
11,760 vs 14,604
dd bs=1M count=512 if=/dev/zero of=test conv=fdatasync
582 MB/s vs 1.2 GB/s
hdparm -Tt /dev/sda
7136, 915 MB/sec vs 17076, 2988 MB/sec
To be honest, it’s really not even close on either front:
Digital Ocean is using slower CPUs, in this case Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz which is 18 cores but … necessarily slower cores because there are so many of them on the die, plus architecturally this is Skylake vs. Coffee Lake.
Clearly these are not NVMe drives Digital Ocean is using. Going to NVMe is a generational leap.
Let’s try the $240/month (48GB, 12 vCPU, 960GB SSD) Digital Ocean instance and see if it gets closer. This machine has multiples of Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz.
sysbench cpu --cpu-max-prime=20000 run
3,180 vs 5,671
sysbench cpu --cpu-max-prime=40000 --num-threads=8 run
10,071 vs 14,604
sysbench cpu --cpu-max-prime=40000 --num-threads=12 run
14,396 vs 17,864
So even the 12 CPU droplet isn’t as fast as our 6 CPU mini-PC, but it’s sporting an older Broadwell era CPU so it wasn’t a particularly fair fight. Disk is a bit faster but clearly not NVMe level.
Let’s try with the $160/month (16GB, 8 CPU, 100GB SSD) CPU Optimized Digital Ocean instance and see how that does. Looks like Intel(R) Xeon(R) Platinum 8168 CPU @ 2.70GHz ooo platinum, fancy! ![]()
sysbench cpu --cpu-max-prime=20000 run
4,636 vs 5,671
sysbench cpu --cpu-max-prime=40000 --num-threads=8 run
13,563 vs 14,604
So the optimized 8 CPU droplet is still not quite fast enough to catch up to our modest 6 core mini-PC, but it’s close! Disks are also definitely not NVMe, and you’re only getting 100GB of it with this droplet anyways.
In conclusion … you are probably getting significantly more than $160/month of “cloud” value out of that $1000 + $29/month mini-PC investment. ![]()
Well yes I’d agree with you there, when it comes to storage specifically. Truly reliable redundant durable storage is a really REALLY hard problem. Shockingly hard… and very expensive to solve. I happily put reliable storage into the hands of AWS S3 / Glacier and it is worth every penny .. but also has become significantly cheaper over time!
For generic compute resources, and when you need “just reasonably statistically reliable” disks, mainstream PCs are stupidly fast and reliable (see previous post), and regularly come in tiny, efficient form factors now that Apple kinda pioneered back in the day.
The secret to a lot of improved PC reliability has been two things
As any server admin worth their salt will tell you, the two most likely things to fail on a server are the power supply, and the hard drive. That’s why servers tend to have RAID arrays and redundant power supplies. Guess exactly which two generic PC parts got orders of magnitude better in the last decade? ![]()
(SSDs from 2012 and earlier, though, were kind of a disaster on the reliability front.)
What do you do when you can’t remote login to your server anymore because it crashed? When it’s in your own place you can still (physically) press that reboot button… And with a VPS you can still reboot it from a web based control panel…
The vCPU in DO are Threads, note actual Core, so your Mini-PC would actually be 12vCPU.
The Memory in Mini-PC aren’t ECC.
The Cloud also allow scaling up and down. So assuming you aren’t running / required CPU for 24 hours. So it should be quite a bit cheaper.
I think there could be some new DO price drop soon. I really wish they could offer 1:1 CPU / Memory instances.
Heavy Azure user here.
Fun fact, the fastest F series azure vm is the same speed, per cpu core and both in a vm, as our 2012 Xeon E5-2670 dev server.
Still happy to use Azure as - for regulatory purposes - we need to be able to quickly spin up machines in secure hosting locations in various countries around the world.
Ah I should have mentioned that in the post – you do get managed power rails with EndOffice so you can do a power cycle reboot via a web UI.
But you’re right, for real server infrastructure you definitely want built in hardware KVM over TCP/IP, which goes by a few different names, for SuperMicro it is IPMI, for Dell it is DRAC, for HP it is ILO, for IBM it is IMM etc.
This doesn’t really matter unless you run hundreds of servers. Some interesting 2018 data here:
RAM used to be among the least reliable component in a computer, but over the last 5 or so years it has improved greatly. In 2018, RAM in general had an overall failure rate of .41% (1 in every 244), but the field failure rate was just .07% (1 in every 1400). So, while RAM is still at risk of failing - especially since you often have 4 or more sticks in a system - after it goes through all our testing and quality control process it is actually very reliable for our customers.
That said, they did see improved field failure rates for ECC of 1:5000 versus 1:1000 for plain old DDR4.
Yep, this is where I landed a few years ago and I’m still there. The provider is responsible for hardware repairs, you get remote control (KVM/IPMI/DRAC), and you can do OS installs remotely using the provider’s provisioning system. Lots of options out there: Hetzner, OVH, online.net.
My current box at OVH (which I use for offsite backup and web hosting) is an SP-32 (Xeon E3-1270v6
4c/8t - 3.8GHz/4.2GHz, 32GB DDR4 ECC 2400 MHz, SoftRaid 3x4TB SATA, 1 Gbps bandwidth) costs about $100/month.
On the following:
https://twitter.com/jacobastultz/status/1096974515593142273
@codinghorror I’d love to see a write up on how you’re tackling this side of things. I’d be fun to see the automation and tooling you’re using, or your monitoring setup. Even a we spend way more time on this than we should, but it’s fun! post would be an awesome read.
Well it is fairly boring.
Setup — simply plug in memory and the ssd and then power it on. The only little tweaky thing is you need to turn on power resume after power loss in the BIOS.
Software — an absolutely bog standard Ubuntu Server 18 LTS install with all defaults. Turn on automatic OS updates, that’s about it.
Testing — documented in the blog post already linked but here it is again https://blog.codinghorror.com/is-your-computer-stable/ this takes about a day as memory testing with 32gb is a few hours, and you should let mprime run overnight.
There is honestly not much more to it than that. Modern Linux is extremely mature, modern PC hardware is easy to set up and exceedingly reliable.
Thanks for the link 
When I see a tweet like the one I posted above, it implies that there exists in the world a very unreliable server. A server that hosts software that takes days to deploy, or needs constant tweaking due to underlying misunderstandings of system settings, or doesn’t have any monitoring, or hasn’t been secured properly, or that goes down unexpectedly, or… (I could go on.)