You might want to update your memory test: Memtest86+ v5.01 supports more CPUs, and can run as a multi-threaded test, which should stress the memory even harder.
One thing I noticed: letting the CPU directly control clock speed switching, rather than the OS, helps some benchmarks a bit. This “Speed Shift” is new to Skylake.
Compared to Speed Step / P-state transitions, Intel’s new Speed Shift terminology, changes the game by having the operating system relinquish some or all control of the P-States, and handing that control off to the processor. This has a couple of noticable benefits. First, it is much faster for the processor to control the ramp up and down in frequency, compared to OS control. Second, the processor has much finer control over its states, allowing it to choose the most optimum performance level for a given task, and therefore using less energy as a result.
Results
The time to complete the Kraken 1.1 test is the least affected, with just a 2.6% performance gain, but Octane’s scores shows over a 4% increase. The big win here though is WebXPRT. WebXPRT includes subtests, and in particular the Photo Enhancement subtest can see up to a 50% improvement in performance.
This requires OS support. Supposedly the latest version of Win10 supports it.
In general I trust AnandTech a lot for benchmarks. They used Chrome 35 for each of the JS benchmark tests. With my mildly overclocked i7-6700k and Chrome 36 x64 on Windows I get 45,013 on Octane and 655 on Kraken which is consistent with what AnandTech saw.
Hmm, I am using Ubuntu 14.04 LTS booter, which has a memory test menu option at startup. I’ll see if I can locate a newer version to use in the future.
I think this depends on the kind of computation you’re doing. Statistics I’ve heard on soft-errors of this kind are on the order of 1 bit error per terabit-year. If you’re building a cluster that’s going to crunch on a single problem for months at a time, where one bit error during the calculation will destroy months of work, and where multiple terabytes of RAM are in use on that calculation, ECC is absolutely worth it. That’s why getting ECC memory support into nVidia’s GPUs was such a big deal for projects like the Titan supercomputer, which has 693.5TiB of RAM running 24/7.
For web server applications like this where the worst thing that happens is one page loads incorrectly, I wouldn’t worry about it so much.
Intel® Product Specification Comparison
Why if I did not know any better I would say someone is trying to artificially segment the market
http://www.cpu-world.com/Compare/492/Intel_Core_i7_i7-6700K_vs_Intel_Xeon_E3-1280_v5.html
As always with Intel, you pay extra for Xeons because they are from better production process. they can run on the same specs but with lower voltage, thus generating less heat. It’s noticeable in huge scale in datacenters when you got thousands of chips.
Also desktop processors rarely run 24/7 with 100% cpu load ![]()
Lots of people doing folding at home, seti at home, or Bitcoin mining run their CPUs at 100% all the time.
Also, as you can see from Intel’s own documentation, and as I already posted above, and you quoted… the chips are virtually identical.
One is a 91w chip that runs at 4.0Ghz the other is an 80w chip that runs at 3.7Ghz. Pretty easy to see where the watts come from, higher clock speed. And one costs about half as much, for more speed. But no ECC.
With respect to memory testing, from my experience running memtest86 (BTW you mistakenly call it memtestx86 in the article, which disturbs my inner perfectionist) alone is not good enough to validate your RAM is fine. In addition to that, I usually also run memtester and cpuburn together — and in some cases it reveals memory errors despite memtest86 results being fine. Just my $0.02
Please note that the Xeon doesn’t have an iGPU.
EDIT:
Also it’s interesting to normalize single threaded performance on frequency:
- 6700K has a +7% freq. boost compared to 3770K
- in Cinebench single threaded benchmark it’s ahead of 3770K by +28.5%
- in the end 6700K leads the 3770K at the same freq. by 19.5% a CPU released 3 years ago
Really interested what the differences are in real-life i.e. Rails benchmarks on both platforms - something tells me it won’t scale to the full +28.5% …
As you yourself note in this quote, the advantage in kraken is just 2.6%, i.e. a tiny fraction of that 28% gain. Also, since anandtech has had 6700k scores up for a while and speedshift isn’t yet in mainstream windows, it’s likely not included in these scores. That’s further corroborated by the fact that the most affected benchmark - WebXPRT - being virtually identical in anantechs 4790k and 6700k benchmarks.
Additionally, if speedshift were the explanation for the gain, you’d expect my personal kraken and octane benchmarks to corroborate anandtech’s scores - instead, my slower 4770k scores considerably higher than anandtechs 4790k.
I’m not sure if it really is due to JS engine benchmarks, but that does fit the facts. In any case, anandtechs scores for 4790k are much, much too low, which makes skylake look better than it really is, by comparison. I’m betting on JS engine improvements partially because moderns browsers try to make it difficult to avoid updating the browser, so it’s plausible they got a faster JS engine without ever intending too.
Regardless: even if JS performance is much faster, almost all other benchmarks don’t mirror this. You might get lucky and find that ruby perf is like JS, but that’s a long shot. It’s much more likely that ruby perf will be like the vast majority of other benchmarked workloads: largely unchanged.
1 Like
Curious if you’ve compared prime95 to something like linpack. From my limited experience testing hundreds of various laptop machines for stability, battery refreshing, and runtime statistics, linpack (intelBurnTest?) seems to kill them a lot faster. They just released a new version: https://software.intel.com/en-us/articles/intel-math-kernel-library-linpack-download
IMHO, prime95 etc are good for benchmarking - having a consistent test across systems is a good idea - but for burn in and stability testing, I much prefer the one made by the chip manufacturer.
Recently I located the source of an overheat fault with my little brother’s rig using furmark and linpack simultaneously that I couldn’t recreate with prime95/mprime running all night. Only other way was random 2 hours of gaming. Furmark+IntelBurnTest got the the failure state in under 10 minutes. It may be a chip-dependent issue, but I remember reading that linpack uses up proportionally more of the on-board circuitry in the CPU to get it’s computation done due to the way it does it floating point calculation - hence a more robust heat generation tool.
I would love to be proven wrong about it, and I have no idea if it makes a difference for servers 
Whenever I have built and overclocked systems, prime95 has been 100% reliable in detecting whether they are stable for me. If prime95 fails overnight, not stable, if it passes… no CPU stability issues at all. I have no idea whether it is the “ultimate” tool but for CPU overclocks it has been incredibly reliable at detecting CPU instability for about a decade now…
Here are some numbers @sam_saffron recorded for Discourse:
build master docker image
build01 16:00 tf21 5:33
This is not a great test since our build was running in a VM on an eight core Ivy Bridge Xeon which has a lower clock speed, and a RAID array of traditional hard drives. Nowhere near an apples-to-apples comparison. But, 3x faster!
running Discourse (Ruby) project unit tests
tf9 8:48 tf21 4:54
This is running the Discourse project unit tests in Ruby. It’s a perfect benchmark scenario as tiefighter9 is exactly the 2013 build described in this blog post and tiefighter21 is exactly the 2016 build described in this blog post. And everything runs on bare metal, Ubuntu 14.04 x64 LTS.
As you can see here, tiefighter21 is almost 2x faster: 528s for the 2013 Ivy Bridge server build, and 294s for the 2016 Skylake server build. Our new Skylake based Discourse servers are 1.8x faster at running the Ruby unit tests in the Discourse project, to be exact.
I hope that data answers your question definitively since you both kept asking over and over and not believing me ![]()
1 Like
@codinghorror wow, that’s just like wow. I wonder if this has any relevance:
EDIT:
I don’t want to be a nit picker it’s just really hard to grasp that switching to Skylake would yield a 1.8x increase solely because of the CPU when the difference between tick/tock on the Intel side barely added +5% performance gains per iteration.
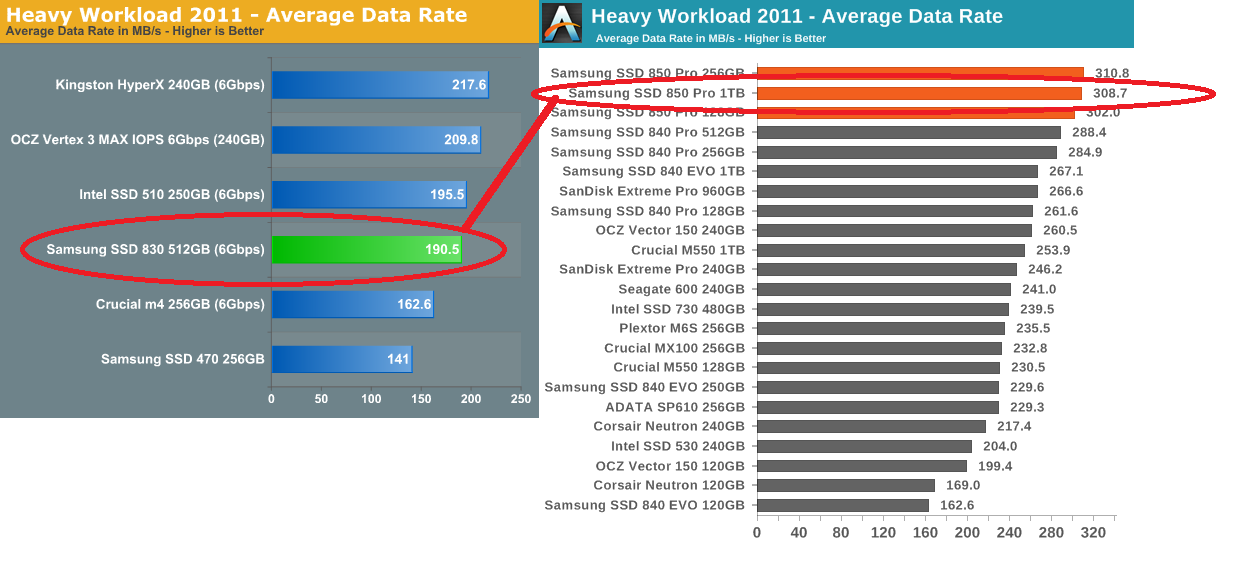
Tiefighter 9 actually has the 512gb Samsung 840 pro because the 830 was no longer being sold at the time that one was built.
Anandtech says avg data rate on the same test for the 840 model is 285 vs the 309 you quoted for the 850 pro. The 850 was mostly more consistent in perf than the 840, not so much faster.
Sorry, I should have mentioned that. I am sure disk is a factor, but I would still expect no less than 1.33× improvement based on the single threaded JS benchmarks at the same clock rate. Plus, the base clock rate is higher as previously noted multiple times – 3.6 Ghz versus 4.0 Ghz, that is more than a 10% improvement on the basis of raw clock rate alone.
Anyway, those are the actual Ruby unit test numbers from the current version of the Discourse project, which is completely open source. You can download it and benchmark these tests yourself if you don’t believe our numbers.
2 Likes
Ok, so I wanted to check if the tests were IO bound:
- pcie ssd: Finished in 6 minutes 18 seconds
- fast microSD drive: Finished in 7 minutes 52 seconds
Clearly IO is not a real issue since the microSD card is orders of magnitude slower than the pcie SSD which would translate in reality to a delta of seconds between let’s say the 830/840 and the 850.
Still 1.8x is huge compared to the IPC improvements and the extra frequency boost. If it’s only the CPU I wonder what exactly makes it that fast.
It’s clearly not the ECC ram that slows down the Xeon E3-1280 V2 since it scores the same as the 3770K:
![]()
Maybe the answer is in these synthetic benchmarks:
Where cache and memory, arithmetic et al are from 1.9x to 2.1x faster compared to 3770 (and the E3-1280 V2)
tl;dr: sometimes synthetic benchmarks do translate to reality. In any case this was quite fun to get to the bottom of it ![]()
![]() wrong
wrong
1 Like
Dan Luu doesn’t think that blindly following Google’s examples is an automatic winner:
Note that these are all things Google tried and then changed. Making mistakes and then fixing them is common in every successful engineering organization. If you’re going to cargo cult an engineering practice, you should at least cargo cult current engineering practices, not something that was done in 1999.
Meanwhile, Joe Chang has a sick burn on Windows 95:
I recall that the pathetic (but valid?) excuses given to justify abandoning parity memory protection was that DOS and Windows were so unreliable so as to be responsible for more system crashes than an unprotected memory system.
It is a very good piece from someone who was there, and well worth reading, but a bit… hand-wavy for my tastes. He does not address all three studies, and does not acknowledge that we are not exactly copying Google from 2000, we are using commodity parts that reflect the state of 2016 computing – which is considerably more advanced than 2000, mostly due to massive integration (hey where did those dual CPU slots and network cards go?) and everything going solid state.
The Puget Systems data was also ignored. But it jibes with what I have experienced. For example in 2011 I knew about so many consumer SSD fails I wrote a whole article about it. Today, we used 24 consumer ssds for the last 3 years in our servers and had exactly zero fail.
Also, this is interesting.
But that solution didn’t work well because the single-thread performance was too low, resulting in higher latency for our web platform
Where else have I heard this… oh yes ![]()
Throwing umptazillion CPU cores at Ruby doesn’t buy you a whole lot other than being able to handle more requests at the same time. Which is nice, but doesn’t get you speed per se.
Also, this is interesting. IEEE publishes study by University of Toronto on RAM corruption issues - far more common than previously estimated.
DRAM’s Damning Defects—and How They Cripple Computers DRAM’s Damning Defects—and How They Cripple Computers - IEEE Spectrum
After reading this blog post and looking at the amount of dicussion about this issue, one could easily argue that the cost of making a decision between ECC and non-ECC is greater than just buying something and living with the consequences.
“As a whole, hardware appears to be continuing the trend of becoming more and more reliable.” https://www.pugetsystems.com/labs/articles/Most-Reliable-Hardware-of-2015-749/